Latest LLMs in the Test: GPT 5.1 Codex Max vs. Gemini Pro 3 vs. Opus 4.5

Photo by Google DeepMind on Unsplash
Last month, I conducted a deep dive into AI frontend generators—vibe coding tools like v0 and Lovable. Since then, the landscape of AI-assisted software development has shifted again. With the release of Claude Opus 4.5 and the hype surrounding "engineering-grade" models, I wanted to move beyond frontend generation and test their capabilities as full-stack engineers.
I took the three current heavyweights—GPT-5.1-Codex-Max, Gemini 3 Pro, and Claude Opus 4.5—and ran them through a rigorous MVP development cycle.
Anthropic claims that "Claude Opus 4.5 is state-of-the-art on tests of real-world software engineering," citing a 74.4% score on SWE-bench. Gemini 3 Pro is nipping at its heels at 74.2%.
But do benchmark numbers translate to shipping products? Let's put it to the test.
The Challenge: Full-Stack AI Development Benchmark
The goal was to build an MVP for an application named Speakit.
- Core Functionality: URL/PDF text extraction, Text-to-Speech (TTS) with playback controls, and a reading interface. The full spec.
- Constraint: Unlike my previous tests of hosted "all-in-one" generators, this test was run locally in Cursor using the respective models. I wanted to test the model's architectural capabilities, not a platform's UI.
The Prompt
Task: Build the Minimum Viable Product (MVP) for the application named Speakit. The complete and definitive feature set, constraints, and scope are provided in the attached document, "Speakit MVP Feature List".
Final Output: Generate the complete, runnable App that fulfills these requirements.
After the initial run, I allowed one iteration cycle:
Task: Go through the list of features one more time thoroughly to verify that the app is feature complete. Implement what is missing.
Benchmark Results: Speed, Quality, and Completeness
1. Performance & Speed
| Metric | Gemini 3 Pro | GPT 5.1 Codex Max | Claude Opus 4.5 |
|---|---|---|---|
| Did it start? | ✅ Yes | ⚠️ After fixes | ✅ Yes |
| Iteration Speed | 🚀 15m 30s (Total) | 9m 20s (Total) | 🐌 22m 00s (Total) |
| Initial generation speed | 11m 30s | 8m 20s | 16m 50s |
| Verify generation speed | 4m | 1m | 5m 10s |
| Lighthouse (Mobile) | 77 | 74 (Slow LCP) | 77 (Slow LCP) |
| Lighthouse (Desktop) | 100 | 98 | 100 |
2. Code Quality & Architecture
Here, I used lizard to analyze the complexity and maintainability of the generated code.
| Metric | Gemini 3 Pro | GPT 5.1 Codex Max | Claude Opus 4.5 |
|---|---|---|---|
| Tech Stack | Next.js, React, Tailwind | Vite, React, Express | Next.js, React, Tailwind |
| NLOC (Lines of Code) | 1038 | 961 | 1714 (High) |
| Avg Complexity (CCN) | 2.1 (Clean) | 3.2 | 3.1 |
| Accessibility | 🟢 95 | 🔴 69 | 🟢 98 |
| SEO | 🟢 100 | 🟡 82 | 🟢 100 |
3. Feature Completeness
| Feature Category | Gemini 3 Pro | GPT 5.1 Codex Max | Claude Opus 4.5 |
|---|---|---|---|
| Core (Input/Extract) | ✅ Mostly (PDF Failed) | ✅ Complete | ⚠️ Mixed |
| Playback (TTS) | ✅ Complete | ✅ Complete | 🔴 Major Failures |
| UI/UX | ⚠️ Functional but Raw | ⚠️ Limited | ✅ Polished |
| Auth & Data | 🔴 Failed | 🟡 Partial | ⚠️ Partial |
Detailed Analysis
Gemini 3 Pro: The Efficient Engineer
Gemini 3 Pro emerged as the most balanced option. It delivered the highest feature completeness and the cleanest code metrics.
- Code Quality: With an Average CCN of 2.1 and only 1038 lines of code, Gemini produced lean, maintainable logic. It didn't over-engineer.
- The Experience: Once I resolved a local npm install issue (likely environment-related), the development flow was effortless.
- The Misses: It stumbled on the "last mile" features—specifically Authentication and Data Persistence, which yielded errors. It also missed the PDF upload requirement.
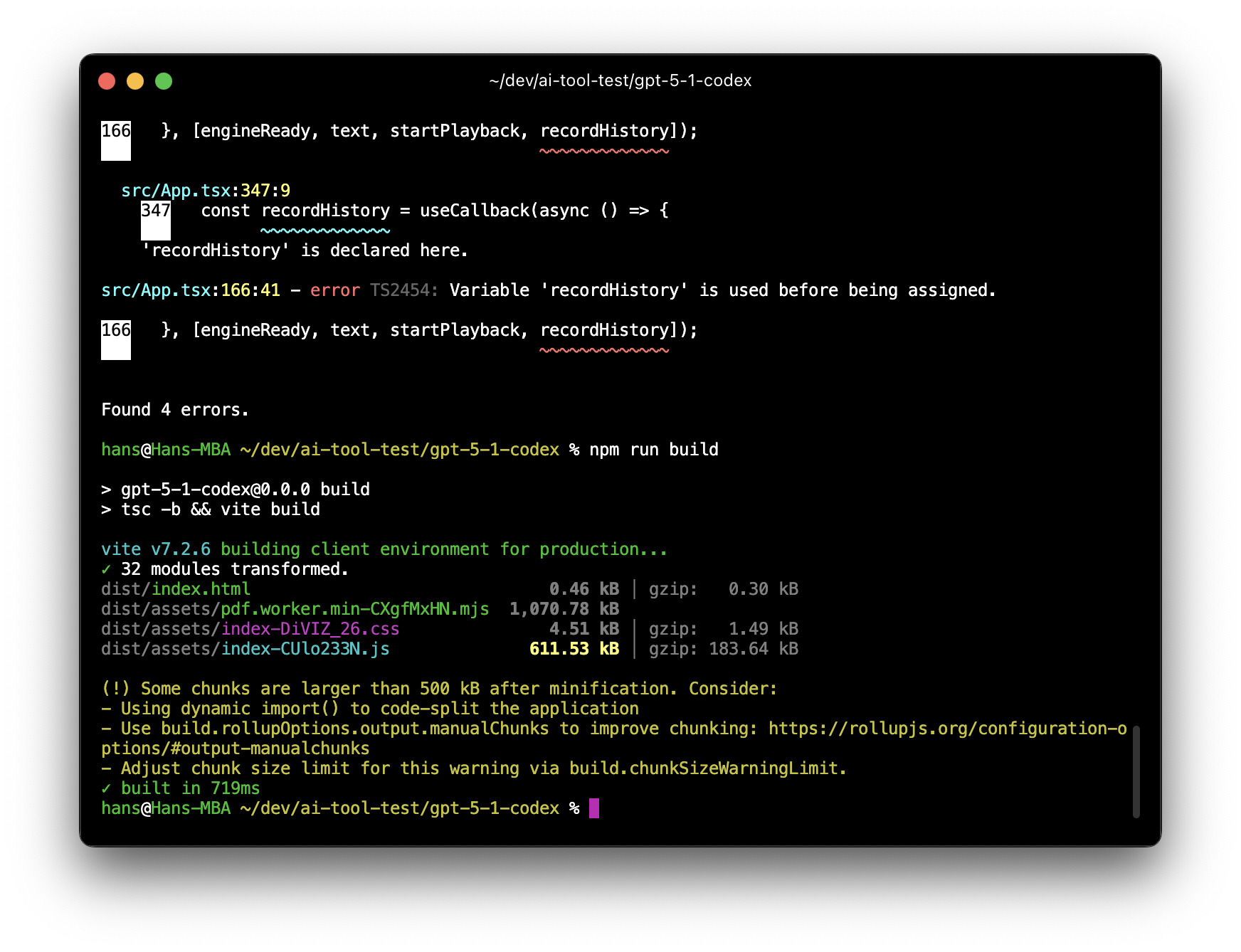
GPT 5.1 Codex Max: The Unconventional Architect
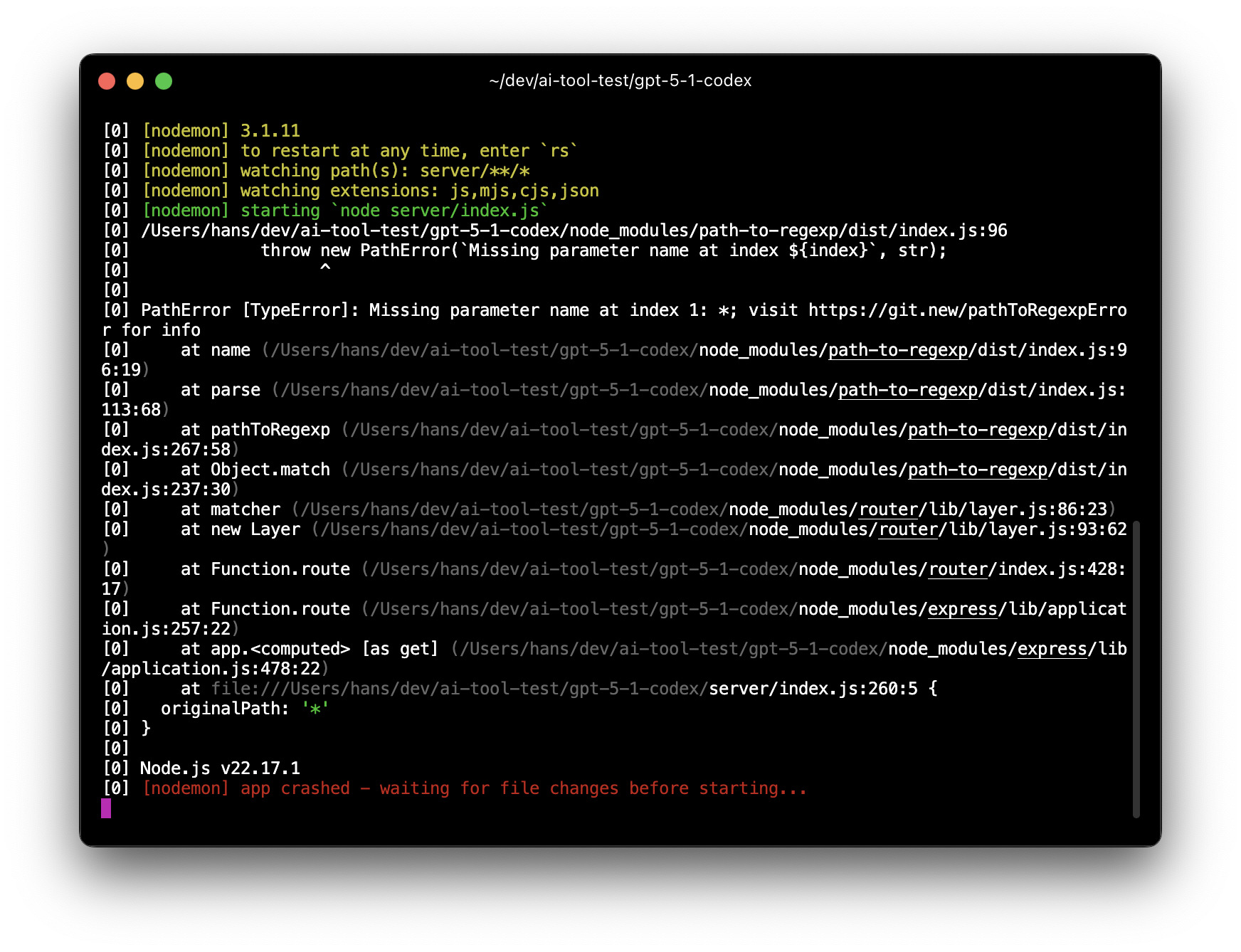
GPT-5.1 made a surprising architectural choice: Vite + Express instead of the standard Next.js stack used by the others.
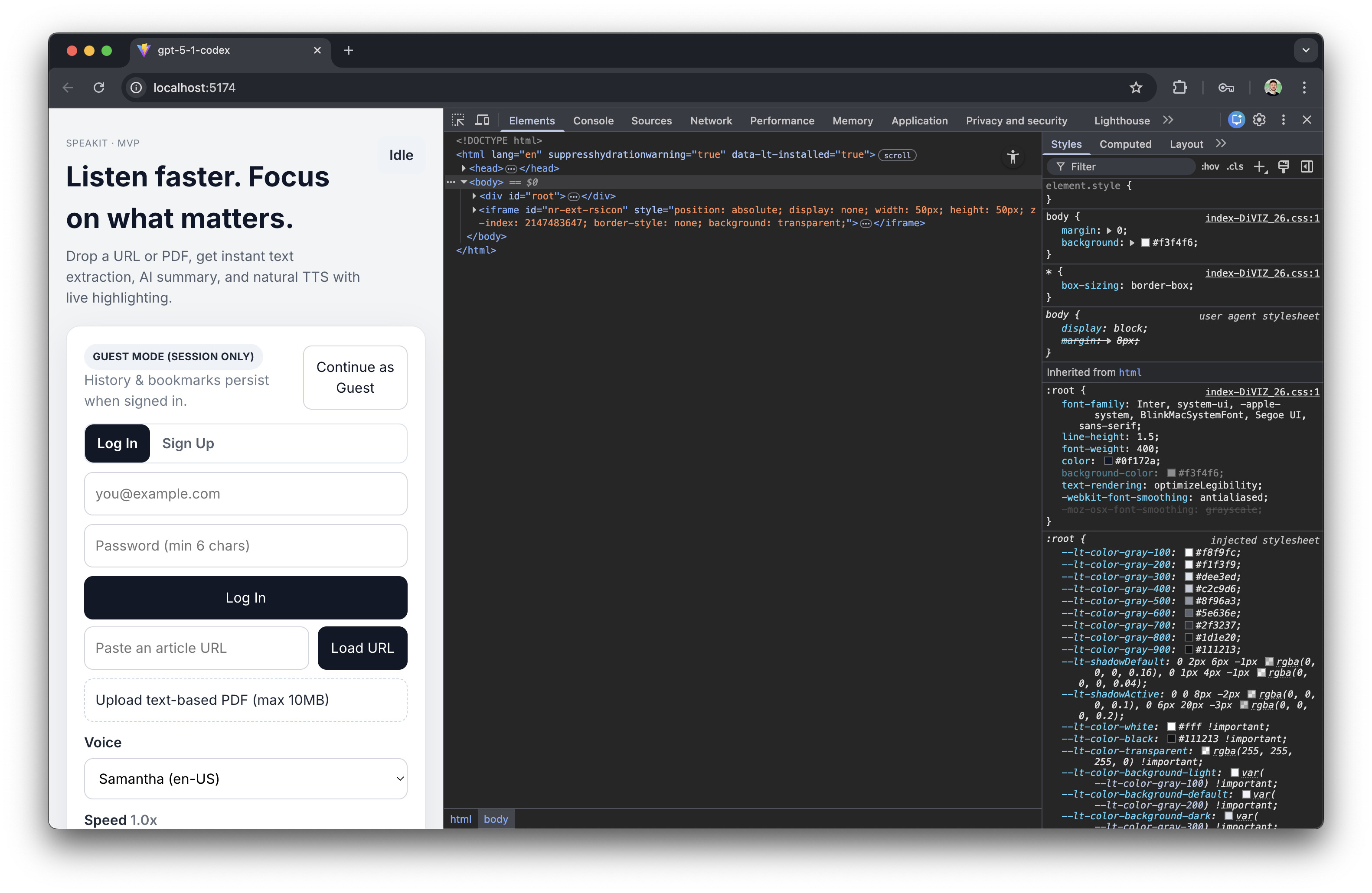
- Pros: It was the only model to successfully implement PDF Text Extraction for well-formatted documents.
- Cons: The "unconventional" stack came with costs. Accessibility scored a low 69, and SEO was mediocre at 82. The build process was fragile, requiring agent intervention to fix initial errors.
- Bug Report: A critical bug remained where text reading would not stop upon page refresh—a state management oversight.


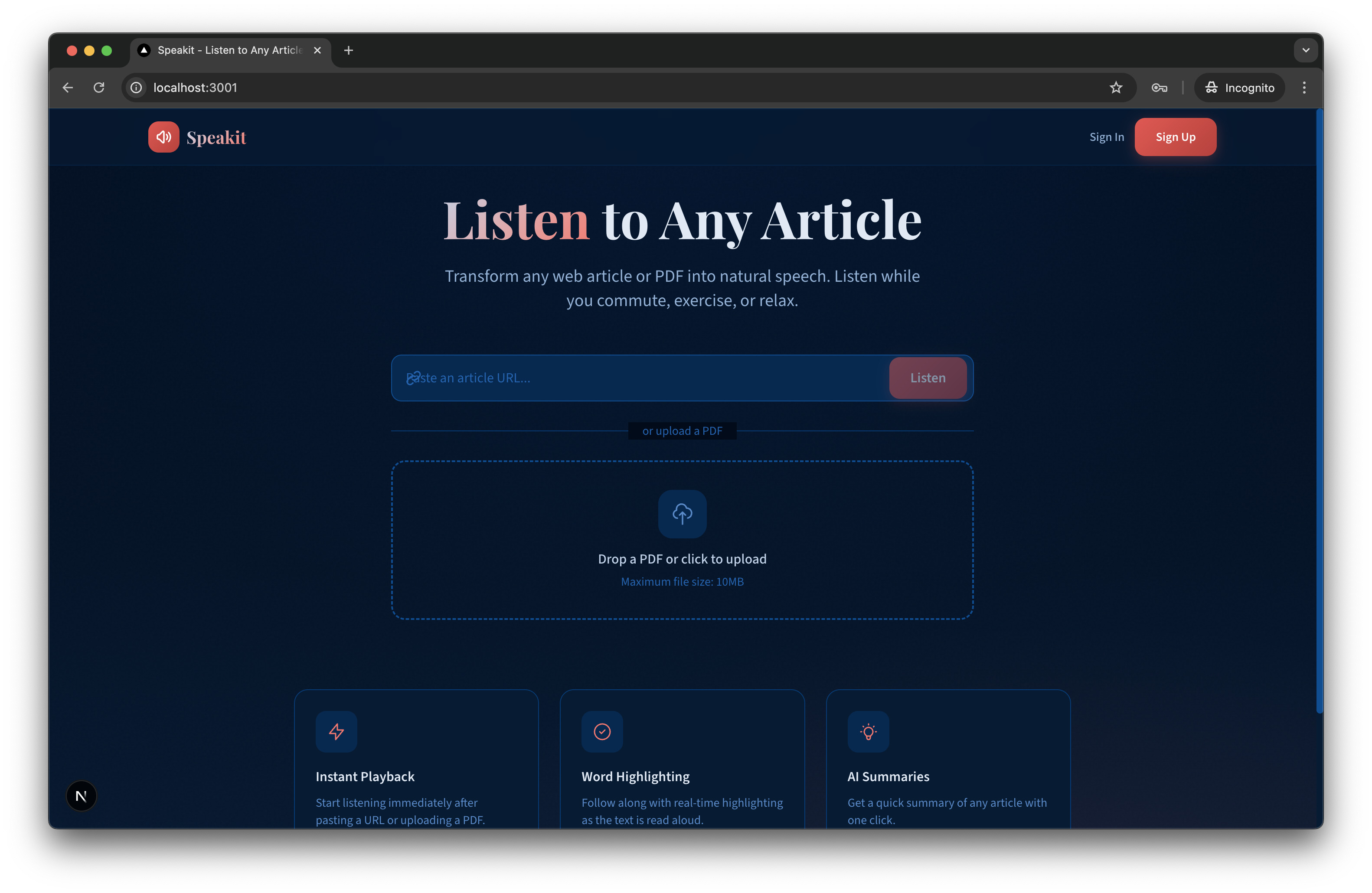
Claude Opus 4.5: The "Vibe" Over Substance
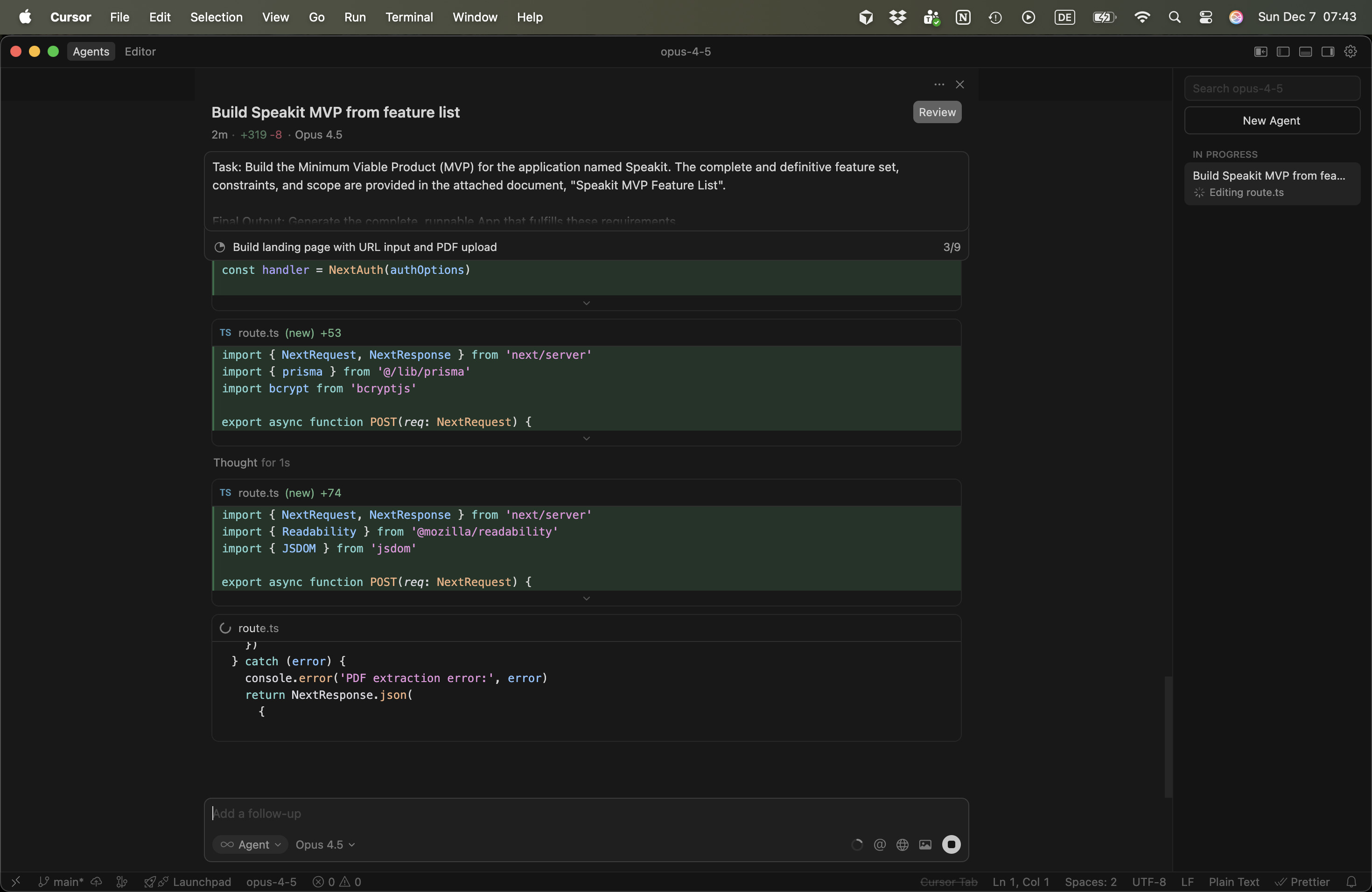
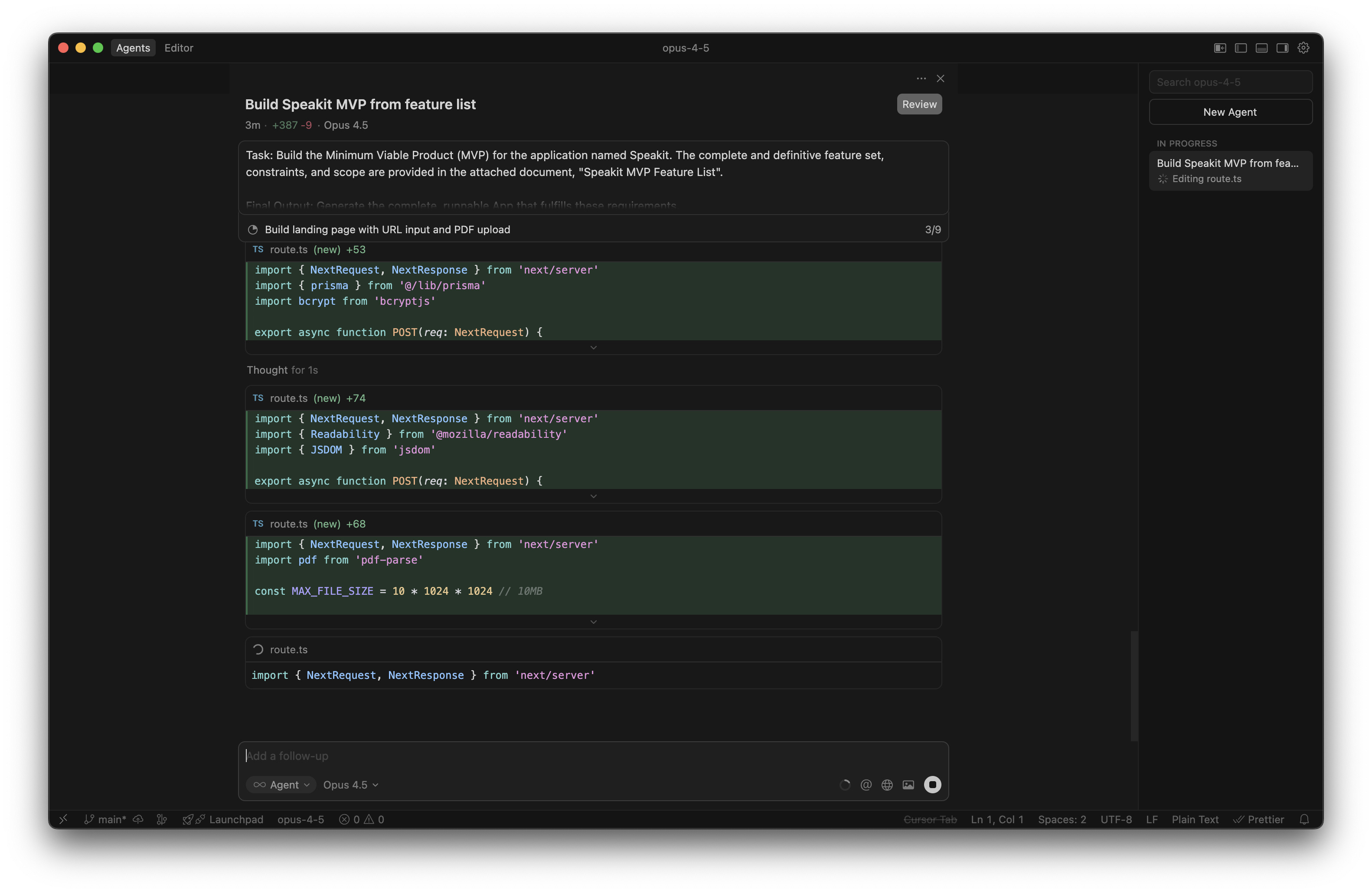
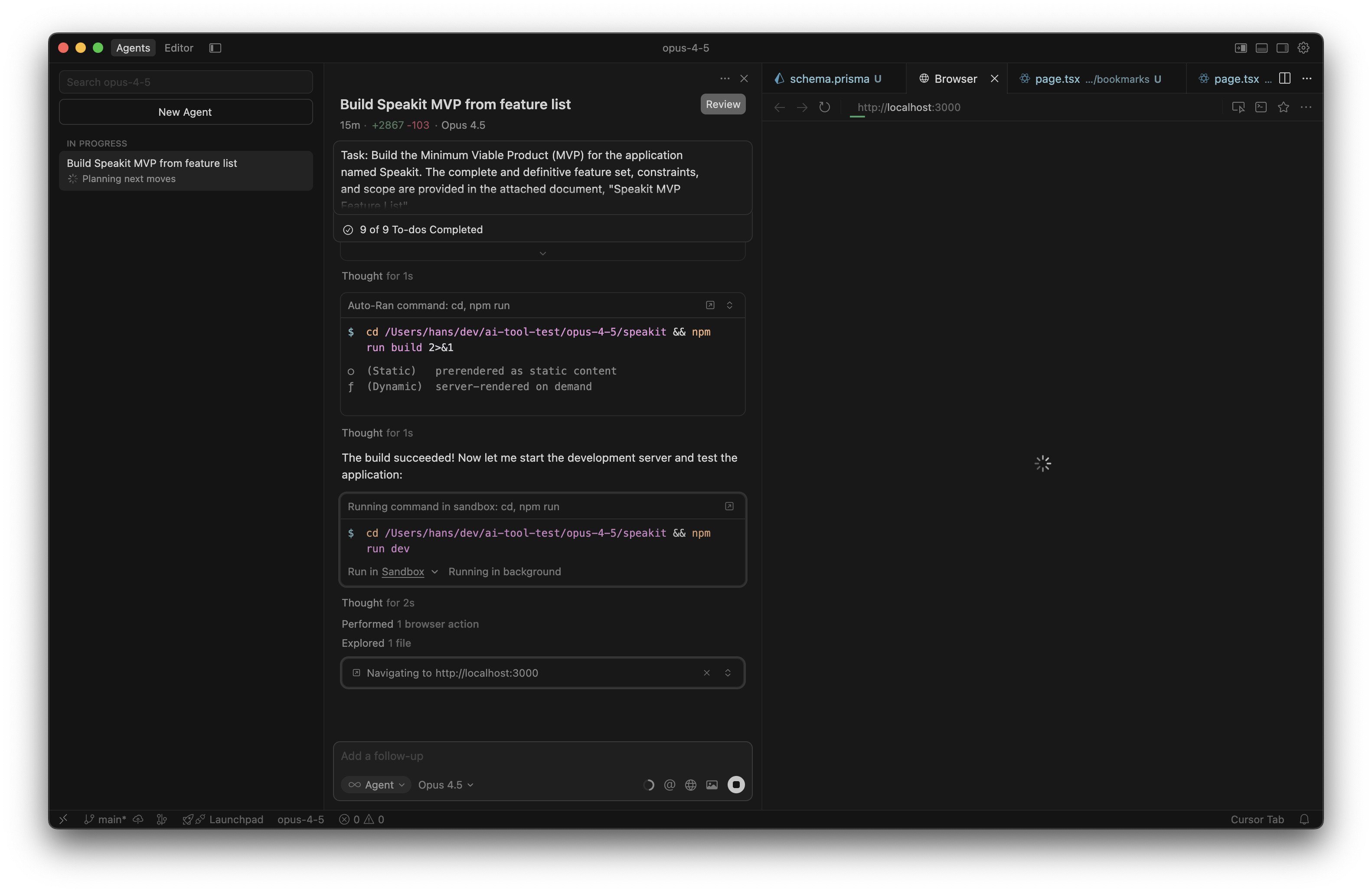
Opus 4.5 was a study in contrasts.
- The Bloat: Look at the NLOC (Net Lines of Code) in the table above: 1714 lines. It generated nearly double the code of GPT-5.1 but delivered fewer working features. This suggests a tendency to hallucinate boilerplate or over-engineer simple components.
- The Visuals: It arguably "understood" the assignment of making a product best. The landing page was launch-ready—appealing and professional.
- The Failure: Despite the beautiful UI, it failed completely on the core value proposition of the app: TTS controls (Speed, Playback) were missing. It prioritized form over function.
Verdict: Which AI Coding Assistant is Best?
After testing three of the most advanced AI coding models, the results reveal a clear gap between benchmark performance and real-world application development.
While both Opus 4.5 and Gemini 3 Pro scored impressively on SWE-bench (~74%), neither delivered a fully functional MVP that met all requirements without intervention.
- Best for Speed & Logic: Gemini 3 Pro. If you want a working app and clean code, start here. It iterates fast and keeps complexity low.
- Best for UI/Design: Claude Opus 4.5. If you need a landing page or a complex UI component, Opus shines, but be ready to refactor the logic and strip out bloat.
- Best for Flexibility: GPT 5.1 Codex Max. If you need to step outside the Next.js bubble (e.g., custom Express backends), GPT is willing to take risks, though it requires more hand-holding on accessibility and build stability.
The takeaway: Benchmark scores don't translate directly to production-ready code. Success currently depends on understanding each model's "personality"—Gemini for engineering, Opus for design—and being prepared to be the Senior Engineer who reviews their PRs. While autonomous coding agents are improving, the human in the loop remains essential for shipping production-grade software.
You can check the generated repositories here:
